
In this example I’ll look at the analysis of clustered survival data with three levels. This kind of data arises in the meta-analysis of recurrent event times, where we have observations (events or censored), k (level 1), nested within patients, j (level 2), nested within trials, i (level 3).
Random intercepts
The first example will consider a model with a random intercept at level 2 and a random intercept at level 3,
$$h_{ijk}(t) = h_{0}(t)\exp (X_{ij}\beta + b_{1i} + b_{2ij})$$
where
$$b_{1i} \sim N(0,\sigma_{1}^{2}) \quad\text{and}\quad b_{2ij} \sim N(0,\sigma_{2}^{2})$$
By assuming a random intercept at the trial level 3, we are assuming that each trial comes from a distribution of trials, which arguably is a strong and perhaps implausible assumption. We may prefer to stratify by trial, but for the sake of illustration, here I’ll proceed with a random trial effect. A second important note is that our covariate effects, 
I’ll start by showing how to simulate data from such a model. Let’s assume we have data from 15 trials, so we generate a trial variable which will indicate which trial the observations come from, and also our trial level random effect
. clear
. set seed 498093
. set obs 15
Number of observations (_N) was 0, now 15.
. gen trial = _n
. gen b1 = rnormal(0,1)Now let’s assume we recruit 100 patients within each trial. We can use expand for this,
. expand 100
(1,485 observations created)
. sort trialwhere expand will replace each existing observation with 100 copies of itself. We then generate a unique patient id variable, and our patient level random effect
. gen id = _n
. gen b2 = rnormal(0,1)We also generate a binary treatment variable, at the patient level,
. gen trt = runiform()>0.5Finally, we allow each patient to experience up to two events, and here we can use expand again,
. expand 2
(1,500 observations created)
. sort trial idNow we can simulate our observation level survival times, by using survsim. I’ll assume a Weibull baseline hazard function with 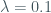


. survsim stime died, distribution(weibull) /// baseline distribution
> lambda(0.1) gamma(1.2) /// baseline parameters
> maxtime(5) /// admin. censoring
> covariates(trt -0.5 /// trt effect
> b1 1 /// random int. lev. 1
> b2 1) // random int. lev. 2By incorporating the b1 and b2 variables into the linear predictor with a coefficient of 1, we have a very convenient way of including random intercepts into our data-generating process.
Note that I’m simulating the recurrent events under a clock-reset approach, i.e. after each event the timescale is reset to 0. In a further example I will look at the clock-forward approach, i.e. one continuous timescale.
We can fit our data-generating model, i.e. the true model, with merlin as follows,
. merlin (stime /// recurrent event times
> trt /// treatment (fixed effect)
> M1[trial]@1 /// random int. at trial level
> M2[trial>id]@1 /// random int. at id level
> , ///
> family(weibull, failure(died))) // distribution & event indicator
Fitting fixed effects model:
Fitting full model:
Iteration 0: log likelihood = -4250.898 (not concave)
Iteration 1: log likelihood = -4183.9242
Iteration 2: log likelihood = -4176.4582
Iteration 3: log likelihood = -4175.4024
Iteration 4: log likelihood = -4175.3996
Iteration 5: log likelihood = -4175.3996
Mixed effects regression model Number of obs = 3,000
Log likelihood = -4175.3996
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
stime: |
trt | -.5449902 .0757995 -7.19 0.000 -.6935545 -.396426
M1[trial] | 1 . . . . .
M2[trial>id] | 1 . . . . .
_cons | -1.99857 .2224338 -8.99 0.000 -2.434532 -1.562608
log(gamma) | .192227 .0259834 7.40 0.000 .1413005 .2431534
-------------+----------------------------------------------------------------
trial: |
sd(M1) | .8217196 .156671 .5654985 1.194031
-------------+----------------------------------------------------------------
id: |
sd(M2) | .971307 .0566649 .8663601 1.088967
------------------------------------------------------------------------------alternatively, we can make our lives easier by using stmixed
. stset stime, failure(died)
Survival-time data settings
Failure event: died!=0 & died<.
Observed time interval: (0, stime]
Exit on or before: failure
--------------------------------------------------------------------------
3,000 total observations
0 exclusions
--------------------------------------------------------------------------
3,000 observations remaining, representing
1,598 failures in single-record/single-failure data
10,166.366 total analysis time at risk and under observation
At risk from t = 0
Earliest observed entry t = 0
Last observed exit t = 5
. stmixed trt || trial: || id: , distribution(weibull)
Random effect M1: Intercept at level trial
Random effect M2: Intercept at level id
Fitting fixed effects model:
Fitting full model:
Iteration 0: log likelihood = -4250.898 (not concave)
Iteration 1: log likelihood = -4183.9242
Iteration 2: log likelihood = -4176.4582
Iteration 3: log likelihood = -4175.4024
Iteration 4: log likelihood = -4175.3996
Iteration 5: log likelihood = -4175.3996
Mixed effects survival model Number of obs = 3,000
Log likelihood = -4175.3996
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
_t: |
trt | -.5449902 .0757995 -7.19 0.000 -.6935545 -.396426
M1[trial] | 1 . . . . .
M2[trial>id] | 1 . . . . .
_cons | -1.99857 .2224338 -8.99 0.000 -2.434532 -1.562608
log(gamma) | .192227 .0259834 7.40 0.000 .1413005 .2431534
-------------+----------------------------------------------------------------
trial: |
sd(M1) | .8217196 .156671 .5654985 1.194031
-------------+----------------------------------------------------------------
id: |
sd(M2) | .971307 .0566649 .8663601 1.088967
------------------------------------------------------------------------------where we reassuringly get the same results. Read more about stmixed in this Stata Journal paper.
Random trial and random treatment effect
Now we consider a second example, but still sticking within a meta-analysis context. In many situations, we would investigate the presence of heterogeneity, i.e. unobserved variability, in any treatment effects. We can do this by modelling a random treatment effect, with the following model.
$$h_{ijk}(t) = h_{0}(t)\exp (b_{11i} + (\beta + b_{12i})X_{ij} + b_{2ij})$$
where
$$b_{11i} \sim N(0,\sigma_{11}^{2}), \quad b_{12i} \sim N(0,\sigma_{12}^{2}) \quad \text{and}\quad b_{2ij} \sim N(0,\sigma_{2}^{2})$$
Once more let’s assume we have data from 15 trials, so we generate a trial variable which will indicate which trial the observations come from, but this time we have a random intercept and also a random treatment effect, which we assume are independent (we could use drawnorm if we wanted to impose correlated random effects),
. clear
. set seed 498093
. set obs 15
Number of observations (_N) was 0, now 15.
. gen trial = _n
. gen b11 = rnormal(0,1)
. gen b12 = rnormal(0,1)Again let’s assume we recruit 100 patients within each trial,
. expand 100
(1,485 observations created)
. sort trialand then generate our unique patient id variable, and our patient level random effect
. gen id = _n
. gen b2 = rnormal(0,1)We also generate a binary treatment variable, at the patient level,
. gen trt = runiform()>0.5Finally, we allow each patient to experience up to two events,
. expand 2
(1,500 observations created)
. sort trial idNow to impose our random treatment effect (varying at the trial level), we can first
generate its overall effect using
. gen trtb12 = (-0.5 + b12) * trtand then simulate our survival times as follows,
. survsim stime died, dist(weibull) /// distribution
> lambda(0.1) /// scale
> gamma(1.2) /// shape
> maxtime(5) /// admin. censoring
> covariates( /// linear predictor
> trtb12 1 /// fixed + random treatment effect
> b11 1 /// random intercept
> b2 1) // random interceptwhere once again we include coefficients of 1 on our random effects. We can fit our data-generating model, i.e. the true model, with merlin as follows,
. merlin (stime /// outcome
> trt /// fixed treatment effect
> trt#M1[trial]@1 /// random treatment effect
> M2[trial]@1 /// random int. at trial level
> M3[trial>id]@1 /// random int. at id level
> , ///
> family(weibull, failure(died))) // dist. & event indicator
Fitting fixed effects model:
Fitting full model:
Iteration 0: log likelihood = -4116.4692 (not concave)
Iteration 1: log likelihood = -4016.0111
Iteration 2: log likelihood = -4009.4162
Iteration 3: log likelihood = -4009.1759
Iteration 4: log likelihood = -4009.1752
Iteration 5: log likelihood = -4009.1752
Mixed effects regression model Number of obs = 3,000
Log likelihood = -4009.1752
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
stime: |
trt | -.5156967 .3010874 -1.71 0.087 -1.105817 .0744238
trt#M1[tri~] | 1 . . . . .
M2[trial] | 1 . . . . .
M3[trial>id] | 1 . . . . .
_cons | -2.027292 .2255663 -8.99 0.000 -2.469394 -1.585191
log(gamma) | .2010559 .0258223 7.79 0.000 .1504451 .2516668
-------------+----------------------------------------------------------------
trial: |
sd(M1) | 1.120972 .2208733 .7618621 1.649351
sd(M2) | .8307332 .1644114 .5636366 1.224402
-------------+----------------------------------------------------------------
id: |
sd(M3) | 1.03136 .0559169 .9273872 1.14699
------------------------------------------------------------------------------And of course, we can replicate this with stmixed using,
. stset stime, failure(died)
Survival-time data settings
Failure event: died!=0 & died<.
Observed time interval: (0, stime]
Exit on or before: failure
--------------------------------------------------------------------------
3,000 total observations
0 exclusions
--------------------------------------------------------------------------
3,000 observations remaining, representing
1,608 failures in single-record/single-failure data
9,961.735 total analysis time at risk and under observation
At risk from t = 0
Earliest observed entry t = 0
Last observed exit t = 5
. stmixed trt || trial: trt || id: , distribution(weibull)
Random effect M1: Intercept at level trial
Random effect M2: trt at level trial
Random effect M3: Intercept at level id
Fitting fixed effects model:
Fitting full model:
Iteration 0: log likelihood = -4116.4692 (not concave)
Iteration 1: log likelihood = -4016.6173
Iteration 2: log likelihood = -4009.4527
Iteration 3: log likelihood = -4009.1758
Iteration 4: log likelihood = -4009.1752
Iteration 5: log likelihood = -4009.1752
Mixed effects survival model Number of obs = 3,000
Log likelihood = -4009.1752
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
_t: |
trt | -.5156688 .3010636 -1.71 0.087 -1.105743 .0744049
M1[trial] | 1 . . . . .
trt#M2[tri~] | 1 . . . . .
M3[trial>id] | 1 . . . . .
_cons | -2.027279 .2255593 -8.99 0.000 -2.469368 -1.585191
log(gamma) | .2010557 .0258222 7.79 0.000 .150445 .2516663
-------------+----------------------------------------------------------------
trial: |
sd(M1) | .8307552 .1643872 .5636896 1.224352
sd(M2) | 1.121014 .2210486 .7616681 1.649895
-------------+----------------------------------------------------------------
id: |
sd(M3) | 1.031359 .0559165 .9273866 1.146988
------------------------------------------------------------------------------This post gave a little taster of simulating and estimating multilevel survival models – go crazy changing the baseline model, more levels, time-dependent effects…the list goes on.
Latest Resources

Specialist subjects
Clinical Trial Services

Specialist subjects
Methods Development

Specialist subjects








