
The Cox model
The Cox model, also known as the proportional hazards model, is a popular statistical tool used to analyse survival data. It was developed by British statistician Sir David Cox, and published in 1972.
It has gained popularity largely by avoiding making parametric assumptions about the shape of the baseline rate in a survival model.
The Cox model estimates the relationship between a set of covariates and the hazard function, which represents the probability of an event occurring at a given time, given that it has not occurred before that time.
The Cox model is a semi-parametric model, meaning that it makes some assumptions about the underlying distribution of the data but does not require complete specification of the distribution.
Instead, it assumes that the hazard function is a product of two components: a baseline hazard function that describes the underlying risk of the event over time, and a set of covariate effects that modify the baseline hazard function for each individual.
Modelling is done on the scale of the hazard function, h(t), which is defined as:
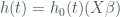
where 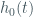
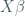
A regular Cox model assumes that the hazard function is proportional over time, which means that the ratio of the hazard functions for any two individuals is constant over time. However, this assumption can be relaxed.
Latest Resources

Specialist subjects
Clinical Trial Services

Specialist subjects
Methods Development

Specialist subjects








